
极品成人故事
热点资讯
- 瑶瑶系列 二战时,波音公司为规避轰炸,曾在工场房顶建造一个假小镇
- 探花 av 我向男闺蜜求婚后,才发现他手机里藏了个一世所爱
- 瑶瑶系列 什么是首发经济?为何火爆?一文读懂
- 瑶瑶系列 9月6日苹果期货收盘下落0.44%,报6793元
- 动漫 色情 真诚,最动东说念主
- 在线av hsex 好意思国中央司令部:多架好意思空军F-16战机已抵达中东
- twitter 自慰 比尔谈选秀:咱们王人知说念浓眉会成状元 我试训时比迈基吉更好
- 露出 porn 和讯投顾投契大拿:A股两周相连收涨,该落袋为安如故大水勇进?
- 妖媚婷儿 勾引 不良钞票“掮客”衰落史
- 白虎 意思 文娱脱口秀 | 《猎罪图鉴2》:活水线的双刃剑
- 发布日期:2025-01-15 17:37 点击次数:76

 自慰 英文
自慰 英文
"要是把参数限度扩大x倍,模子才智就会赢得y倍的进步" ——这条支抓着AI领域几年狂飙突进的Scaling Law,似乎正在走向特别。
从GPT-3到GPT-4,从BERT到PaLM,AI的进化史险些即是一部算力竞赛史。但最近的发展却给这个故事带来了转移:Claude 3在看护3.2B高下文的同期显赫压缩了参数限度;Anthropic的研究东说念主员公开暗示"更大的模子未必更好";DeepMind在近期论文中更是直指Scaling Law在迫临东说念主类解析才智时可能存在根人性纵脱。当千亿参数、万亿tokens渐渐成为标配,陋劣的堆料堆算力似乎越来越难以带来质的飞跃。
这不禁让东说念主想考:
是咱们对Scaling Law的意会还不够深入?
照旧这条旅途自己就存在天花板?
基座大模子的下一个松弛点究竟在哪?
咱们至极挑选了一批在知乎活跃的AI领域答主的精彩恢复,他们中既有来自科技公司的一线从业者,也有对AI发展永久善良并深度研究的时间博主。信服这些不雅点能为咱们提供更多对于AI发展的想路与洞见。
本次研讨四肢知乎「互联网破局者」系列步履的至极推敲,以下为精选的答主恢复,内容基于答主公开拓布的不雅点进行整理。更多精彩恢复,点击阅读原文赶赴知乎检验硅星东说念主的发问“Scaling Law要撞墙了吗?如何找到基座大模子的改日所在?”
1
@傅聪Cong
四肢一个AI从业者,个东说念主不雅点“Scaling Law撞墙”,实足不是媒体吹得那么骇东说念主闻见!它只是意味着——改日通用东说念主工智能的发展旅途应当当令地转向。
底下说说我的意义:“Scaling Law撞墙”的问题为什么激发了AI圈如斯泛泛的烦燥?
其实东说念主们挂念的问题,并不是一个实验不雅察功令失效与否的小问题,而是其背后可能存在的大模子后果进入瓶颈期的问题:要是大模子不行够不息”越大越好”了,那么OpenAI先前抛出的改日大模子才略特出东说念主类顶级水准的预言,可能无法完了。除了题主问题配景中的信息,更让东说念主挂念的音书是,堪称AI圈“卓伟”的秃子哥爆料:“猎户座”——人人解析的GPT-5——内测后果不行达到预期。访佛的演义念音书还包括Anthropic的Claude的新版块的后果也低于预期。就好比家里孩子初中升高中(GPT-3到GPT-3.5)、高中升大学(GPT-3.5到GPT-4)都很获胜,散伙研究生却若何都考不上了。
随之而来的,不单是是对时间发展的担忧,更严重的后果是投资的断流。不言而谕的是,面前的LLM经济即是一个砸钱的商业,钱没了就更不可能scaling下去了,统统的投资方都会给LLM有关的企业和从业者施加更大的压力,而且更审慎地看待面前企业经由LLM的盈利才智。说不美妙的,LLM行业可能会存在“大踩油门,大踩刹车”的泡沫危境!
说了这样多,咱也不行事后诸葛亮地怪“Scaling Law”的提倡者当初咋不好好作念实验。那么“Scaling Law”到底撞墙了嘛?
咱们再来再行望望Scaling Law那张闻明的图:
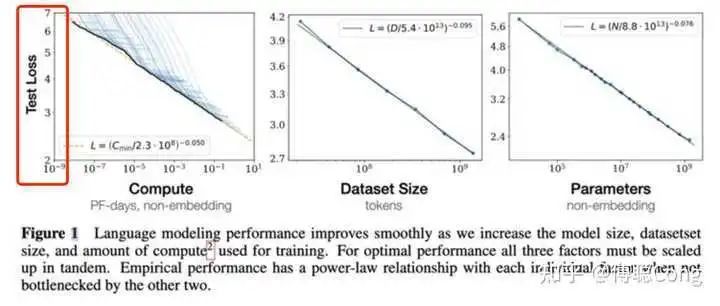
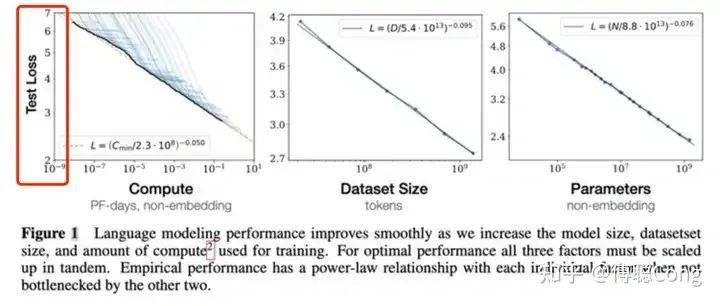
防备,这里的纵坐标是test loss。也即是说,所谓的scaling才智,是瞄准“测试耗费”这个方针的,是以感性地讲,莫得东说念主应许过,跟着参加的数据、算力、参数的增多,模子的”才略“会线性进步。
接下来,咱们来翻新两个阅读这张图的误区:
test loss和模子的才智面前来看并不存在一个线性有关的关连。正巧相背,当test loss低到一定进程,东说念主对于模子输出后果的利害的感知才智会弱化。这件事情,我其实在我之前的一篇论文的研讨里聊到过:
https://www.zhihu.com/question/599186065/answer/3019505570?utm_campAIgn=shareopn&utm_content=group3_myAnswer&utm_medium=social&utm_psn=1858611794765025280
纵轴的坐标亦然log scale的!这里画重心!在双log scale的坐标刻度建立下,这篇论文的研究者画出了很漂亮的一条接近直线的散伙。也即是说,想要test loss线性下跌,需要参加的算力、数据等资源成指数速率上涨!
OK,问题的根源找到了。
那么寻找基座模子改日的短期内的所在,咱们不错从以下两个方面起原:
当先!亦然最弥留的事情!即是回到原点!完善刻下或寻找更好的评价体系。面前的评价体系,难以和东说念主的解析对王人,也难以全面地评价大模子的才智。不完备的评价体系,不利于模子的良性迭代。也不利于构建良性的市集环境。就好比许多模子都堪称我方在一些benchmark的推崇上特出GPT-4,但给用户的体感,却并非那样。变相饱读舞、培养出了一群cherry pickers。
探索其它的scaling type。除了“trAIning phase scaling”,最近的研究和家具还展示出不同的scaling形态。举例multi-agent的scaling,不需要一个超等大模子,而是饱读舞更多不同的人人小模子进行勾搭,强化“模块化”上风;以及“inference phase scaling”,给大模子更多的“想考”的时辰以及更多的context信息,让它“找到”正确的谜底,这也更合乎类东说念主智能驱动的遐想设施论,毕竟咱们东说念主类处罚复杂问题的时候主要通过“慢想考”系统来构建动态的处罚旅途,同期,也不需要把统统任务有关的信息都“事先”挂念到脑子里。就好比雇主让你作念一个PPT,你是不需要先背下来PPT的逐字讲稿,再进行画图、遐想的。
临了,天然我必须承认时间发展的“惯性”——统统东说念主都基于刻下的transformer架构进行增量研究——存在一定的积极作用,但我个东说念主期待的通用东说念主工智能,尤其是基座模子,应当是拙劣耗,更接近生物能的。
刻下的这种范式,即便咱们在前文所述的两个方面有所松弛,亦然不可抓续的。
https://epoch.AI/blog/can-AI-scaling-continue-through-2030 这份调研答复指出,到2030年,按照Scaling Law去检修一个“GPT-6”所需的算力是充足的,但当先卡脖子的,很可能是电力资源。同期,届时检修一次GPT-6,需要上百亿好意思金,换个计量单元,卖掉我司都不够检修一次的,容错率是低的不行再低了......
但愿到2030年,咱们能找到愈加可抓续的通用东说念主工智能的研发旅途,一个让社会各界都能有参与度的方式,而不是面前这种成本通吃的方法。因为我信服,无论是针对这种时间的研发回是监督,都需要更广范围的合作。
1
@凡俗
英伟达的黄仁勋在CES 2025上展示了一张PPT,标题为「从一种到三种Scaling Laws」,其纵坐标标注为智能进程(Intelligence),强调了东说念主工智能发展过程中三种重要的Scaling Laws:预检修(Pre-training)、后检修(Post-training)和测试时推理(Test-Time Scaling)。

具体来说:
Pre-training Scaling(预检修)
这是AI模子检修的运转阶段,以GPT早期模子为代表。特质是依赖超大限度神经汇集和海量互联网数据,行使无监督学习设施,通过预测下一个字符或词语进行检修。
智能进程:此阶段的检修方针是构建一个通用的谈话模子自慰 英文,但输出散伙相对基础,穷苦复杂的语境意会和逻辑推理才智。
局限性:天然检修数据量宽绰,但穷苦针对性的优化,模子推崇的智能进程受到一定纵脱。
Post-training Scaling(后检修)
代表AI模子的进化阶段,以ChatGPT的原型为例。重要性情是通过东说念主类反应的强化学习(RLHF)进一步对预检修模子进行优化和养息,以提高模子的交互才智和东说念主类对王人度。它的检修方式是模子把柄东说念主类提供的反应评分,优化其恢复内容和作风,慢慢具备更天然、更贴合东说念主类抒发民风的谈话才智。
智能进程:在这个阶段,AI模子不仅能生成通顺的文本,还能展现一定进程的创造性和逻辑推理才智,其天花板即是GPT-4o。
局限性:得当需要复杂对话和任务料理的场景,如智能客服、写稿援手和老师器具,但对于需要高强度推理以及复杂任务依旧不行胜任。
Test-Time Scaling(测试时推理)
代表AI智能发展的最新阶段,以ChatGPT的o系列模子为例,专长于推理和复杂任务处理。它的责任旨趣基于后检修模子,通过进一步细化任务扩充进程,将复杂任务领悟为多个可考证的小法子(微推理模块),以提高得胜率和准确性。接受"用时辰换空间"的政策,通过更高的筹画资源和更长的推理时辰通常任务完成率的显赫进步。
智能进程:至极得当数学、物理和化学等需要逻辑分析与多步考证的问题,推崇出更强的推理和决策才智。
局限性:这种模式的资源和时辰成本较高,适用于对精度条款极高的应用场景。
不错看到,这三种scaling law带来的智能进程进步口舌常显赫的,不错侧面解说,scaling law短时辰内不会失效,只是和会过另一种神气推崇出来。
改日的AI还会不息朝着进步智能以及扩展应用畛域的门道走下去,前者依旧需要多数的东说念主类反应数据,scaling才刚刚起始;后者需要更需要的Agent的反应数据,也才刚刚摸到门槛。
1
@桔了个仔
所谓Scaling Law,俗语说即是「力大砖飞」。Scaling Law指的是,模子性能跟着模子参数目、数据量和算力的增多呈现的幂律关连。
不外,跟着参数目的不息增多,互联网数据似乎不够用了Ilya 在 NeurIPS 2024 中提倡的不雅点是「预检修行将散伙」,原因是跟着筹画才智进步,互联网上的数据量并莫得彰着增长。

不外,无论如何,他讲的,其实只是在pre-train阶段遭遇瓶颈。事实上,Scaling Law不错发生在不同的维度。
当先讲讲基座大模子如何不息保抓Scaling Law。
合成数据(Synthetic Data)
其实这个想路是work的。举例sora即是使用了多数的合成数据,传说Sora可能接受了UE5、Unity的合成数据四肢检修集。
但这个想路照旧pre-train阶段进步设施,天然喂合成数据应该也能进步模子性能,但个东说念主以为其旯旮效应一经出现了彰着递减。可能其他有打算会更有性价比。
但合成数据有另一个克己,即是有助于Alignment。具体不错参考@李rumor 这篇著作[1]。https://www.zhihu.com/people/rumor-lee
反向scale
既然通过数据带来的旯旮进步不那么具有性价比了,那么是否不错尝试以更少参数完了同样后果?毕竟东说念主类智能并不是地说念靠数据的,东说念主类的大脑就140-160亿神经元,况且还并非一说念神经元都激活了。天然,大模子参数数目不行顺利等价于东说念主脑神经元数目,但有没一种可能,面前多数大模子都是「参数多余」的?
其实这个想法,在2022年Deepmind发表了一篇论文《Training Compute-Optimal Large Language Models》[2]中就被叙述过。这个论文最弥留的一个论点是:面前统统大谈话模子都是检修不充分(undertrained)的。
这个论文还检修了一个检修了700亿参数的模子 Chinchilla,在许多下贱任务上的性能显赫特出了许多参数更大的模子,举例 Gopher (2800亿), GPT-3 (1750亿) 等。
这篇论文让许多公司露出到,堆叠参数的性价比可能不高,优化检修集,优化检修设施,致使提倡新架构,都可能带来新的收益。
非Transformer架构
许多非Transformer架构,能以更少参数目完了同样后果。举例RWKV。举例 @PENG Bo 在这篇恢复里先容到https://www.zhihu.com/question/6833253550/answer/55768424495,RWKV-7 0.1B参数的基座模子,而且还没作念任何post-training,就能完了底下的后果
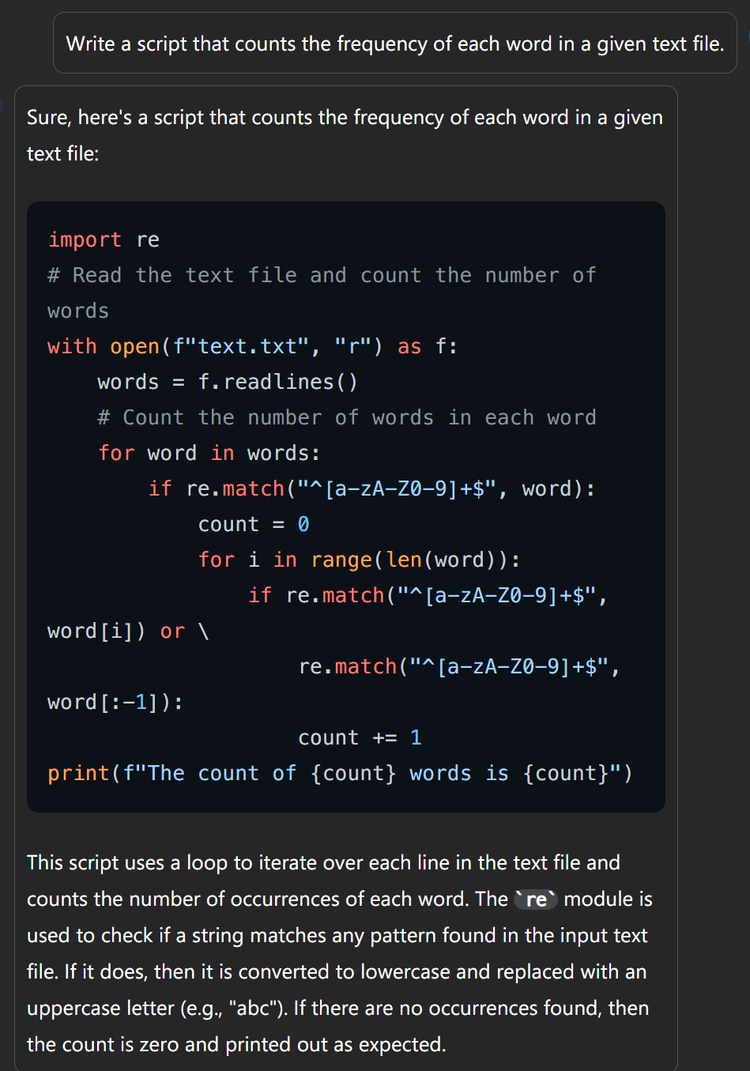
除了RWKV,其他非Transformer架构还包括Mamba,S4等等,它们都是接受用 recurrent(轮回)结构去替代 attention。
以上都是从基座模子所在起程。除了基座模子,还有别的所在
强化学习的Scaling Law
o1的发布,让人人看到,通过强化学习(Reinforcement Learning),让大模子self-play,不错不息进步其推理才智。具体不错看 @张俊林 的这篇分析[3]https://www.zhihu.com/question/666992324/answer/3624700849
这个所在赢得了许多AI公司的认同,举例Qwen推出了QwQ(我可爱这个名字),DeepSeek推出了R1,天工大模子推出了Skywork o1等等。揣测是2025年最有价值的所在之一。
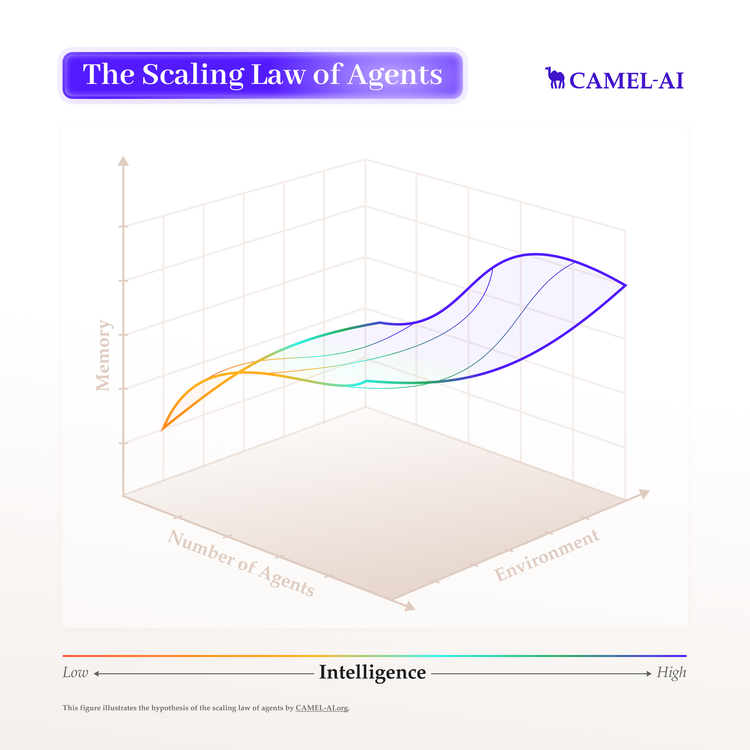
Muiti Agent的scaling law
举例@Guohao Li李国豪 在研究的所在[4]:multi agent系统的scaling law,会发现跟着参加系统的Agent数目增多,其推崇出来的智能越来越强
能够就先写这样多,仅四肢投砾引珠。
1
@Trisimo崔想莫
Scaling Laws天然没撞墙。
不行说咱们松弛不了光速,是狭义相对论撞墙了。
这种性能撞墙,正巧即是Scaling Laws所预示的。
撞墙的是谁?即是数据,数据是最受制于物理宇宙的纵脱的。
参数不及?商用模子比如GPT-4o和Sonnet的参数不及,不错吃更干净的蒸馏,吃合成数据,数据是喂不饱大参数母模子的,是以参数不是问题。
算力不及?面前暂时足了,算力的最终本色是电力,面前暂时有核电站的订单顶着。
1. 东说念主工智能公司的“数据渴慕”,一经达到了令东说念主发指的进程。(不要以为公域数据穷乏,只是说说的汉典,这帮一经输不起的成同胞,无所不必其极。)
例子:Anthropic的爬虫,爬了iFixit网站,一天爬了一百万次。就像你说:接待你来我家!散伙,对方一天来了一百万次。艾麻,的确草!Dario Amodei天天搁那宣传“合成大法好”,散伙把东说念主家的窝都薅秃了。——这不是爬虫,这是蝗虫。
2. 算法带来的进步微弱,Scaling Laws主管。本色上,神经汇集是结构单调的,这种单调性使得优化算法莫得太大赋闲不错插入。暴力仍然是主管,夯就完事了。为什么OpenAI的GPT好用?数据,尤其是他们的后检修精华数据。
例子:我看了DeepMind的研究科学家Felix Hill的心路自叙(这是我见过的文笔最佳的AI研究员),他坦言模子算法带来的进步相等微弱,但每天仍然需要面对它。咱们不行说Felix的抑郁自尽与这项责任的无力感顺利有关,但很彰着,这种鼓励极小的责任,加快了他的悲催。假定算法带来的进步极大,那么Felix一定能从责任中体验到致力感。
3. 强化学习Reasoning带来的范式调换,但仍然有限。RL Reasoning在R什么东西?是一种想维方式,仅此汉典?是的,仅此汉典。他们莫得在R学问自己,只是在R一种套路。
例子:GPT-5预检修遭遇阻力,原因是穷苦有余的数据量和数据万般性,OpenAI招募专科团队来为数学和代码题编写解答,同期再加上OpenAI推理模子产生的数据。要是说,数据是有余的,或者说推理是全能的,OpenAI何苦此举?直观先于推理,莫得GPT酿成的学问直观,那么推理Agent无米难为炊。——也许OpenAI改日会变成半个数据研发公司,是的,我说的是数据研发,挺好笑的吧。
以上是面前OpenAI,Anthropic,Google御三家的情况,其他的公司面对的情况可能会更严峻。
改日的所在,要是改日是AI主导的宇宙,那么数据的相聚和标注会是中枢责任。
数据这个故事,不是一经达到了瓶颈,而在预示一个“后数据期间”。这会是一个不雅念翻新的问题。一个面向确凿场景的AI,它需要私域数据。也许改日的模子微调的公司,会把最大的元气心灵放在为客户相聚数据标注数据,数据即智能(一种低泛化性的智能)。咱们是否要质疑通用模子的适合性?
1
@咸蛋
scaling的问题许多东说念主没搞显着。
要是仔细测试模子就会发现,模子没看法处罚未知问题,哪怕是推理模子,遭遇未知问题本色上是在刻下内容上作念扩展,也即是,要是一个外部学问模子莫得,那么它推理亦然搞不定这个问题的。
面前许多东说念主把这个上限归结为scaling的问题,我以为这是不合的,这个分为两个部分,一个是深度,一个是广度。
深度代表最强的o3,其实作念题方面十分特出了,可是o1测试下来,许多模子穷苦的学问库内容,它依然会在造作的解析上进行推理,即是所谓幻觉,那么这个问题是scaling的问题吗?
我以为不是,中枢点照旧模子的学问库对王人问题,即是说模子无法处罚这个问题,并非模子不会,而是它的底层解析和你要处罚的问题有偏差。
也即是它意会的东西,其中某个要津,和你要责任完成的方针,有歪曲,归并个API名字,他用其他库的内容替代了,这就导致了模子的不健壮性,也即是所谓的性能瓶颈,跟着模子数据越大,这种箝制施行上更严重了,同义词更多,权重糊涂接近极限,中间的任何细小的学问箝制都会导致模子的举座推理法子造作,是以嗅觉性能险些无法进步了。
这即是scaling撞墙的本色,也即是说,数据质地卡死了scaling而不是数据限度。
那么一个面向统统东说念主的通用模子,他的里面权重势必是平衡的,也即是说它不行对用户成立单独数据对王人,比如两个东说念主责任环境不同,那么归并句话的预见可能就不同,你的9.11是数字,他的9.11是日历。
那么散伙就会导致这种不健壮性,也即是说你不可能用辅导词精准标注每个法子的详备指代,那么这个东西的存在进到想维链,就势必导致推理过程的不健壮性。
也即是所谓的scaling失效问题,必须构建出更高质地的数据,才能提高模子的底层性能,而高质地数据的构建成本相等高,是以openAI无奈只可接受强化微调,让模子我方生成推理链路,东说念主类来修正的设施来构建增强的数据去检修GPT5,之前顺利扩大数据限度的设施在GPT5上头失效了,也即是模子进一步扩大数据集和参数后,模子的学问广度提高了,深度则不敢越雷池一步,是以GPT5卡死两次不得已一说念转向合成数据。
是以要想进一步提高模子的才智,这里我有一些想法,即是要完了对数据的深度清算,还有动态数据匹配。
第一个的预见即是,要挖掘数据标注的极限,一个优质数据,不错作念数据增强实验,能否通过优化优质数据来提高分数,是一个相等值得研究的所在。
第二个则是让模子能够自主对王人用户,不是后检修设施,而是模子能够通过用户使用过程的反应,自我反想推理养息模子输出内容,无法处罚的内容不错恳求用户匡助,把用户输入的外部学问进行内化,也即是所谓的成长型模子架构,不是固定权重的模子,模子能访佛东说念主一样反想,自我养息,访佛自动化lora,及时强化微调的嗅觉,可是更轻量。
另外我还有一个相等有预见的想法,要是有研究大模子的大佬不错望望是否可行,即是把模子参数进行标注和预测标注,把模子权重数据和标注数据混杂,作念成一个可生养模子。
什么预见呢,即是作念一个模子生成模子的大模子,这个模子的生成散伙即是模子权重文献。
要是这个所在能有松弛,可能是一个相等值得研究的所在,大模子自我生养,端到端的进化模子。
是以不必挂念大模子没所在,所在多的很,AI远未撞墙。
在多位答主的深度探讨中,咱们看到了对Scaling Law多维度的想考:从大模子演进的三阶段论,到test loss的本色剖析;从合成数据与反向scale的时间探索,到学问对王人与数据质地的创新想路;从数据瓶颈的久了反想,到多智能体勾搭的改日瞻望。这些研讨揭示了一个重要事实:所谓的"瓶颈",也许并非是Scaling Law自己的局限,而是咱们对AI发展范式的解析需要跳跃新的维度。
正如量子力学的发展最终松弛了经典物理的藩篱,AI的下一次飞跃可能同样需要对根蒂范式的再行想考:从单一的参数限度彭胀,到多维度的质地进步;从静态的学问存储,到动态的解析演进;从追求极致算力,到探索高效且可抓续的架构。这不仅是时间旅途的选拔,更是AI发展形而上学的反想。
值得深想的是自慰 英文,在这个临界点上,咱们不应被"瓶颈"二字所困,而应将其视为一个机会——再行凝视AI发展的根蒂命题,探索更富联想力的可能性。毕竟,正如东说念主类解析的演进从未留步,AI的进化或然也正在酝酿着新的范式转移。
- 自慰 英文 磋议当代社会中的伪娘局势2025-04-16